My research interests lie broadly in artificial intelligence and dynamical systems. I enjoy applying theoretical mathematical concepts to develop new machine learning algorithms for a variety of practical real-world dynamical systems. In particular, my current focus is on sequential decision-making problems involving high-dimensional state spaces. My research at the department of Finance and Risk Engineering of the NYU Tandon School of Engineering uses the financial application domain as a challenging real-world dynamical system environment in which to advance machine learning. It involves the application of theoretical mathematical principles such as the theory of dynamical systems, abstract algebra and group theory, representation theory and topology, information geometry, optimization and statistics. I have also worked in diverse applications such as physics, healthcare and medicine, and computational social science. The long-term mission of our research group is centered on continuing the development of machine learning theory for real-world dynamical systems using applications in finance and beyond.

My Google Scholar page can be found here.
Publications
Agent-Based Modeling (ABM)

Amine Mohamed Aboussalah, Cheng Chi, Chi-Guhn Lee
Submitted to Scientific Reports, Nature, 2022
Modern financial markets are experiencing an increase of interdependencies among organizations such as banks, companies, or even countries. This connectivity can amplify financial shocks on the underlying assets, spread financial contagion, and lead to additional failures of institutions in the network. The study of cascade failure is called systemic risk. Our research aims to create a more realistic computational systemic risk environment model and to develop an algorithm to optimize the financial network structure using quantum computing in order to tackle the intractability problem with scaling to large realistic networks. Our goal is to assess whether our quantum methodology helps to reduce the number of cascade failures and hence better mitigate systemic risk.

Amine Mohamed Aboussalah
In preparation for Physica A: Statistical Mechanics and its Applications, ELSEVIER, 2023
Understanding how institutions interact is critical to mitigating industry wide (unsystematic) risk and market wide (systematic) risk. Quantum computing is useful for modeling the many interactions in large graphs necessary to study these risks. Our goal is to create a quantum energy-based financial market representation to better identify the emergence of critical financial baskets associated with periods of financial stress and to determine the time and space complexity of the graph algorithms. We aim to solve real world finance problems using a commercially available quantum computer (D-Wave 2000Q), and compare those solutions to ones obtained through classical algorithms.
 Recursive Time Series Data Augmentation
Recursive Time Series Data Augmentation
Amine_Mohamed_Aboussalah, Minjae Kwon, Raj G Patel, Cheng Chi, Chi-Guhn Lee
International Conference on Learning Representations (ICLR), 2023
Time series observations can be seen as realizations of an underlying dynamical system governed by rules that we typically do not know. For time series learning tasks we create our model using available data. Training on available realizations, where data is limited, often induces severe over-fitting thereby preventing generalization. To address this issue, we introduce a general recursive framework for time series augmentation, which we call the Recursive Interpolation Method (RIM). New augmented time series are generated using a recursive interpolation function from the original time series for use in training. We perform theoretical analysis to characterize the proposed RIM and to guarantee its performance under certain conditions. We apply RIM to diverse synthetic and real-world time series cases to achieve strong performance over non-augmented data on a variety of learning tasks. Our method is also computationally more efficient and leads to better performance when compared to state of the art time series data augmentation.
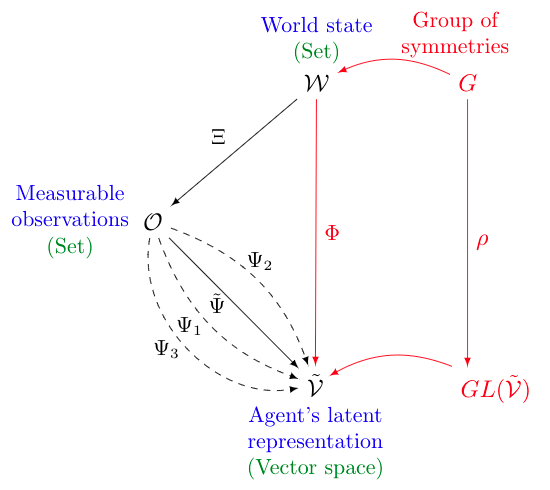
Amine Mohamed Aboussalah, Chi-Guhn Lee
In preparation for Mathematics of Operations Research, INFORMS, 2023
We hypothesize that the concept of symmetry augmentation is fundamentally linked to learning. We propose a new representation that enables symmetry augmentation and show that it can enhance any reinforcement learning model. Mathematical background and proofs are presented.
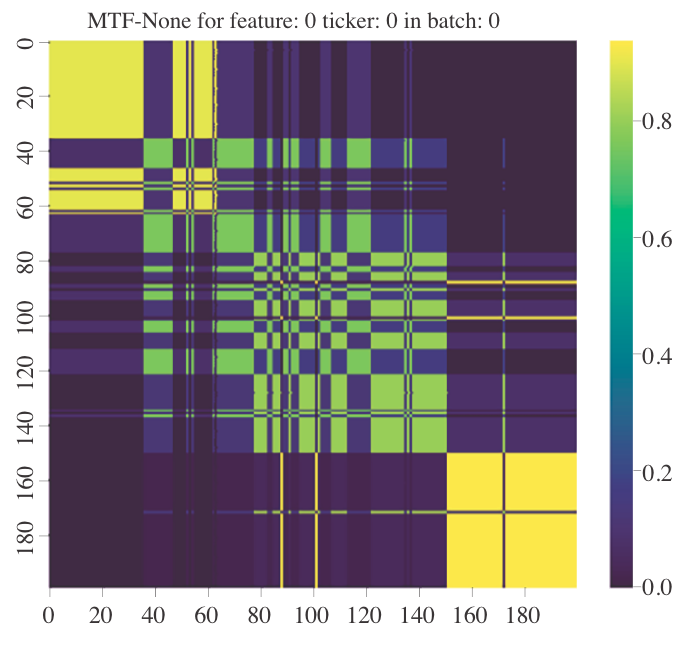
Amine Mohamed Aboussalah, Chi-Guhn Lee
In preparation for Quantitative Finance, Taylor & Francis Online, 2023
We hypothesize that the concept of symmetry augmentation is fundamentally linked to learning. We propose a new representation that enables symmetry augmentation and show that it can enhance any reinforcement learning model.

Amine Mohamed Aboussalah, Ziyun Xu, Chi-Guhn Lee
Quantitative Finance, Taylor & Francis Online, 2021
The Markowitz Mean-Variance Optimization (MVO) and the Kelly formula are two different well-known methodologies for portfolio theory, both of which would allocate the portfolio optimally but from a totally different viewpoint. The contribution of this paper was to bring together these two concepts in the RL context. More specifically, I used an actor-critic RL approach where I leveraged the Kelly theory for the critic to evaluate the policy of RL models based on growth. I also leveraged the Markowitz theory for the actor by defining a multi-objective and risk-sensitive RL reward function based on total return. I adapted multi-channel convolutional neural network (CNN) receptive fields to noise filter multi-type financial data and treated the data without making the Markov assumption. This paper introduces the new concept of cross-sectional representation for deep reinforcement learning and combines it with time series analysis. The importance of this work is that the agent focused on return is evaluated based on growth, resulting in a more reliable agent. The addition of cross-sectional analysis complements time series analysis and results in improved decision-making.
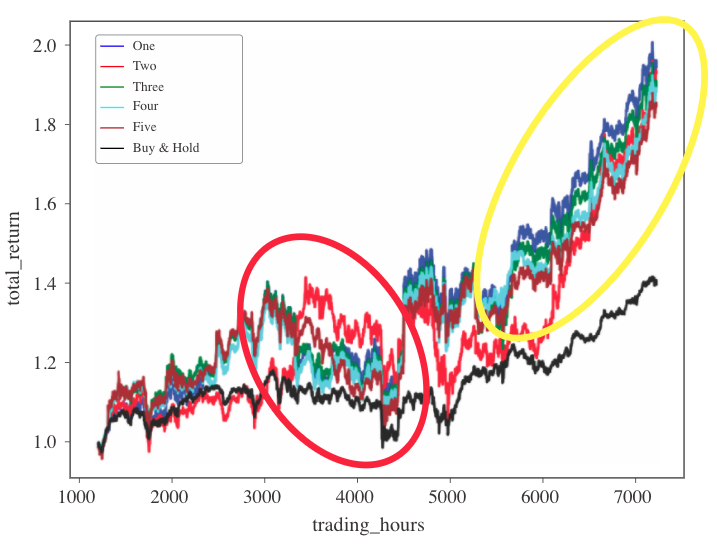
Amine Mohamed Aboussalah, Chi-Guhn Lee
Expert Systems with Applications, ELSEVIER, 2020
I developed a history-dependent policy gradient algorithm that allows continuous control over multiple assets. I defined the concept of “Time Recurrent Decomposition” that takes into account the temporal dependency between decisions, a result that proved to be critical since financial problems are path dependent and not Markovian as usually assumed in the Markov decision process formulation of RL. Stacking recurrent network structures allows the algorithm to maintain the flow of information through different time steps and balance long-term trends versus short-term losses. I developed a risk-sensitive RL policy by utilizing the Sharpe ratio, which is a deviation risk measure, as the expected utility function for the RL algorithm. I adapted Bayesian optimization to simultaneously control the portfolio constraints and the policy network hyperparameters in an online setting. Since many real-world problems are not Markovian, the importance of this work is the development of a risk-sensitive RL agent without relying on the MDP formulation commonly used in RL.
 Curbing Xenophobia? Assessing the Impact of the COVID 19 Mobility Curbs on Anti Refugee Sentiment in Turkey
Curbing Xenophobia? Assessing the Impact of the COVID 19 Mobility Curbs on Anti Refugee Sentiment in Turkey
Amir Abdul Reda, Amine Mohamed Aboussalah, Semuhi Sinanoğlu
World Bank Policy Research Working Papers, The World Bank, 2021
American Political Science Association (APSA) Meeting & Exhibition, 2021
Is COVID-19 increasing or decreasing sympathy for refugees? What are the impacts of COVID-19 mobility curbs on sympathy? What does this tell us about the policies that can be implemented to improve cohabitation between host communities and forcibly displaced populations during pandemics? In this paper, we explore answers to these questions in the context of Turkey by examining sentiment data from Twitter and mobility data from the Google Mobility Report. Our findings suggest that when debates over the pandemic remain separated from national debates over refugees, widespread stigma toward forcibly displaced populations currently hosted in a given country can be avoided. This means that efforts must be made to keep the issue of refugees separated from national debates about the pandemic, all the while fostering a climate of societal bonding against the pandemic.
 Forecasting Local Warming: Missing Data Generation and Future Temperature Prediction
Forecasting Local Warming: Missing Data Generation and Future Temperature Prediction
Amine Mohamed Aboussalah, Christopher Neal
Cahiers du GERAD, Group for Research in Decision Analysis, 2016
Global warming is a much discussed topic as it sparks debate for shaping government policy and how humans should behave in reaction to climate change. Global warming can be evaluated with a local perspective by looking at temperature trends in an isolated region. In this work we predict a local warming trend for Canada’s capital city Ottawa, Ontario up to the year 2040 using optimization and machine learning techniques.
Equation-Based Modeling (EBM)

Amine Mohamed Aboussalah
In preparation for Journal of Machine Learning Research, JMLR, 2023
This work lies at the intersection of Reinforcement Learning (RL) and Partial Differential Equations (PDEs). Option pricing has been regarded as a difficult problem because the general solution usually involves solving high-dimensional PDEs which are very complicated to solve in practice. We investigate the use of RL to solve high-dimensional Black-Scholes type PDEs for pricing options under increasingly realistic dynamical regimes.
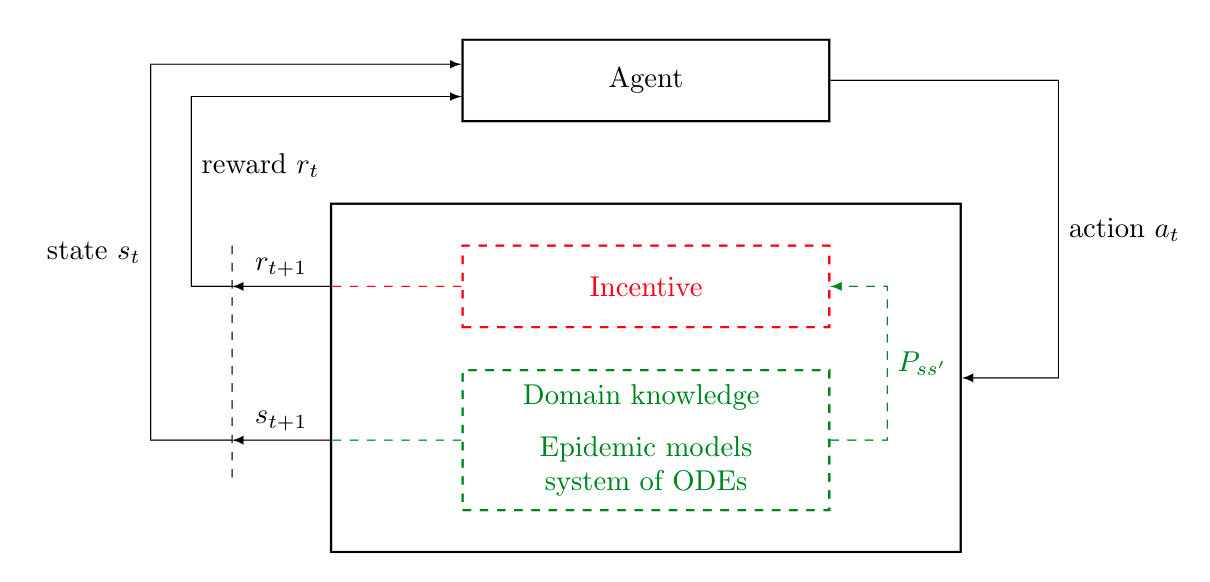
Amine Mohamed Aboussalah
In preparation for Nature Machine Intelligence, Nature, 2023
Policy makers around the world are focused on strategizing and executing various measures to control the spread of the most severe pandemic in recent times. These measures and interventions bear substantial humanitarian and economic costs. Understanding the impact of these interventions is crucial to developing effective strategies to control the pandemic spread. Current techniques focus on methods to forecast the pandemic spread and utilize them to design heuristic strategies. In order to be effective, these heuristic strategies require highly accurate long term forecasting models which can be complicated to develop. We address this problem by reformulating the objective as end-to-end pandemic control instead of pandemic forecasting. We propose a generic, novel Markov Decision Process based formulation for pandemic control that incorporates domain knowledge and benefits from existing epidemiological models. The proposed framework facilitates the use of Reinforcement Learning to find the optimal policy for the sequential decision making problem of end-to-end pandemic control where the goal is to minimize long-term negative humanitarian and economic impacts of the pandemic.

Chen Chi, Amine Mohamed Aboussalah, Elias B. Khalil, Juyoung Wang, Zoha Sherkat-Masoumi
Neural Information Processing Systems (NeurIPS), 2022
We propose RLCG, the first Reinforcement Learning (RL) approach for Column Generation (CG). Unlike typical column selection rules which myopically select a column based on local information at each iteration, we treat CG as a sequential decision-making problem, as the column selected in an iteration affects subsequent iterations of the algorithm. This perspective lends itself to a Deep RL approach using Graph Neural Networks to represent the variable- constraint structure in the LP formulation. We perform an extensive set of experiments using the publicly available BPPLIB benchmark for the Cutting Stock Problem (CSP) and Solomon benchmark for the Vehicle Routing Problem with Time Windows (VRPTW). RLCG converges faster and reduces the number of CG iterations by 22.4% for CSP and 40.9% for VRPTW on average compared to a commonly used greedy policy.
Other
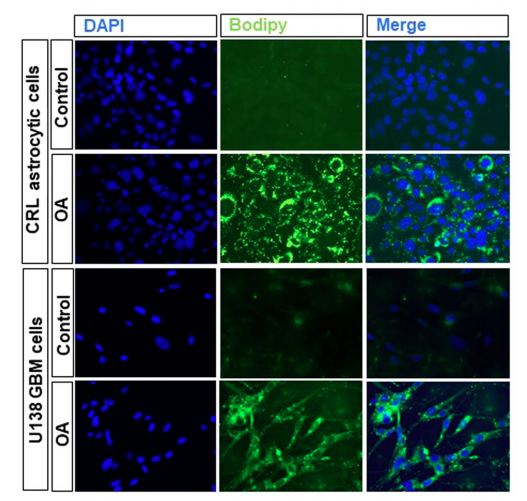 Lipid Accumulation and Oxidation in Glioblastoma Multiforme
Lipid Accumulation and Oxidation in Glioblastoma Multiforme
Bouchra Taïb, Amine Mohamed Aboussalah, Mohammed Moniruzzaman, Suming Chen, Norman J. Haughey, Sangwon F. Kim, Rexford S. Ahima
Scientific reports, Nature, 2019
Analysis of brain tissues from Glioblastoma multiforme (GBM) patients shows that lipid droplets are highly enriched in tumor tissues while undetectable in normal brain tissues.
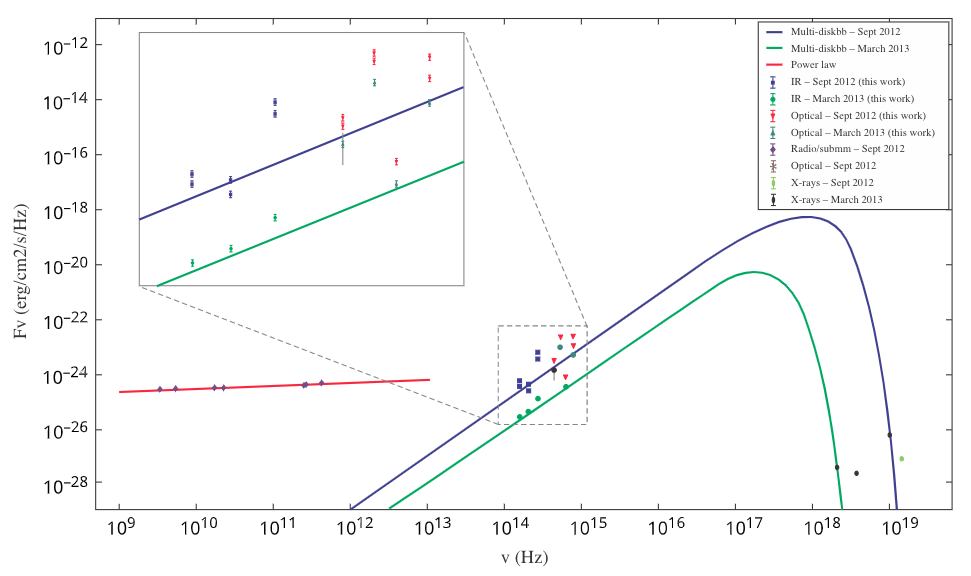 Infrared and Optical Observations of the Black Hole X-Ray Transient Swift J1745-26
Infrared and Optical Observations of the Black Hole X-Ray Transient Swift J1745-26
Alicia López-Oramas, Sylvain Chaty, Alexis Coleiro, Amine Mohamed Aboussalah
Submitted to Monthly Notices of the Royal Astronomical Society, 2015
Published in Astronomy & Astrophysics, 2020
We present the results of the infrared (IR) and optical observations of the counterpart of the black hole (BH) X-ray transient Swift J1745-26 during September 2012 rise and March 2013 decay outburst. We determined the system is a low-mass X-ray binary (LMXB).
 Can the Problems Faced by the Boeing 787 “Dreamliner” be Explained by Boeing’s Innovative Supply Chain Strategy?
Can the Problems Faced by the Boeing 787 “Dreamliner” be Explained by Boeing’s Innovative Supply Chain Strategy?
Amine Mohamed Aboussalah, Tiphaine de Pommereau, Raphaël Leyder, Julien Wagon, Toussaint Wattinne
Paris Air Show (Salon du Bourget), HEC Paris, 2013
This work aims at understanding the role played by the innovative supply chain strategy put in place by Boeing in the numerous problems encountered by its 787 Dreamliner program.
Seminars and Presentations
- Exploiting Structure in Reinforcement Learning to Mitigate Risk in Real-World Financial Control Problems. Peter Carr Brooklyn Quant Experience (BQE) Seminar Series, New York University (2023).
- A Deep Reinforcement Learning Framework for Column Generation. Institute For Operations Research and the Management Sciences (INFORMS) Annual Meeting (Cluster: Reinforcement Learning for Decision Making in Networks and Combinatorial Spaces), Indianapolis (2022).
- Quantum Graph Partitioning Delays Cascade Failure Phase Transition in Financial Networks. Workshop on Quantum Computing and Operations Research, The Fields Institute, Toronto (2022) (presented by my collaborator Cheng Chi).
- Exploiting Symmetry in Real-World Reinforcement Learning. 62nd Canadian Operational Research Society (CORS) Annual Conference (Cluster: Artificial Intelligence and Machine Learning), Toronto (2021).
- High-Dimensional Continuous Reinforcement Learning For Finance. 62nd Canadian Operational Research Society (CORS) Annual Conference (Cluster: Finance and Risk Management), Toronto (2021).
- High-Dimensional Reinforcement Learning for Finance. Bank of Montreal (BMO) Capital Markets AI Labs, Toronto, Canada (2021).
- High-Dimensional Reinforcement Learning for Portfolio Management. Canadian Imperial Bank of Commerce (CIBC) Capital Markets, Toronto, Canada (2020).
- Continuous Control with Deep Dynamic Recurrent Reinforcement Learning for Portfolio Optimization. 4th Industrial Academic Workshop on Optimization and Artificial Intelligence in Finance, The Fields Institute, Toronto (2018).
- Optimization-Based Approach for Simulating Interstellar’s Wormhole. Institute for Data Valorization (IVADO), Montreal, Canada (2017).
- Forecasting Local Warming: Missing Data Generation and Future Temperature Prediction. Canada Excellence Research Chair in Data Science for Real-Time Decision-Making (CERC-DS4DM), Montreal, Canada (2016).
- Can the Problems Faced by the Boeing 787 be Explained by Boeing’s Innovative Supply Chain Strategy? Paris Air Show (Salon du Bourget), Paris, France (2013).